Сравнение сервисов для анализа документов AWS Textract, Azure Document Intelligence и Ripper Service от Технологики
Бизнес все чаще и чаще предпочитают отдать искусственному интеллекту извлечение данных из документов: при таком подходе меньше ошибок и выше скорость обработки документов. И все чаще звучит вопрос — каким решением пользоваться и к какому подрядчику пойти за оказанием услуги?
Мы сделали сравнительный обзор двух популярных решений от лидеров рынка по обработке документов — AWS Textract, Microsoft Azure Document Intelligence и собственного решения Ripper Service. Сравнивали решения по нескольким основаниям: по производительности, по результатам извлечения значений из форм, а также по стоимости.
Надеемся, что данная статья будет полезна руководителям компаний, которые уже задумались о применении ИИ для массовой обработки документов.
Методология
Мы анализируем работу наиболее популярных на западе сервисов AWS и Azure на основе распознавания англоязычного налогового документа, предоставленного Intuit ProSeries Tax Organizer.
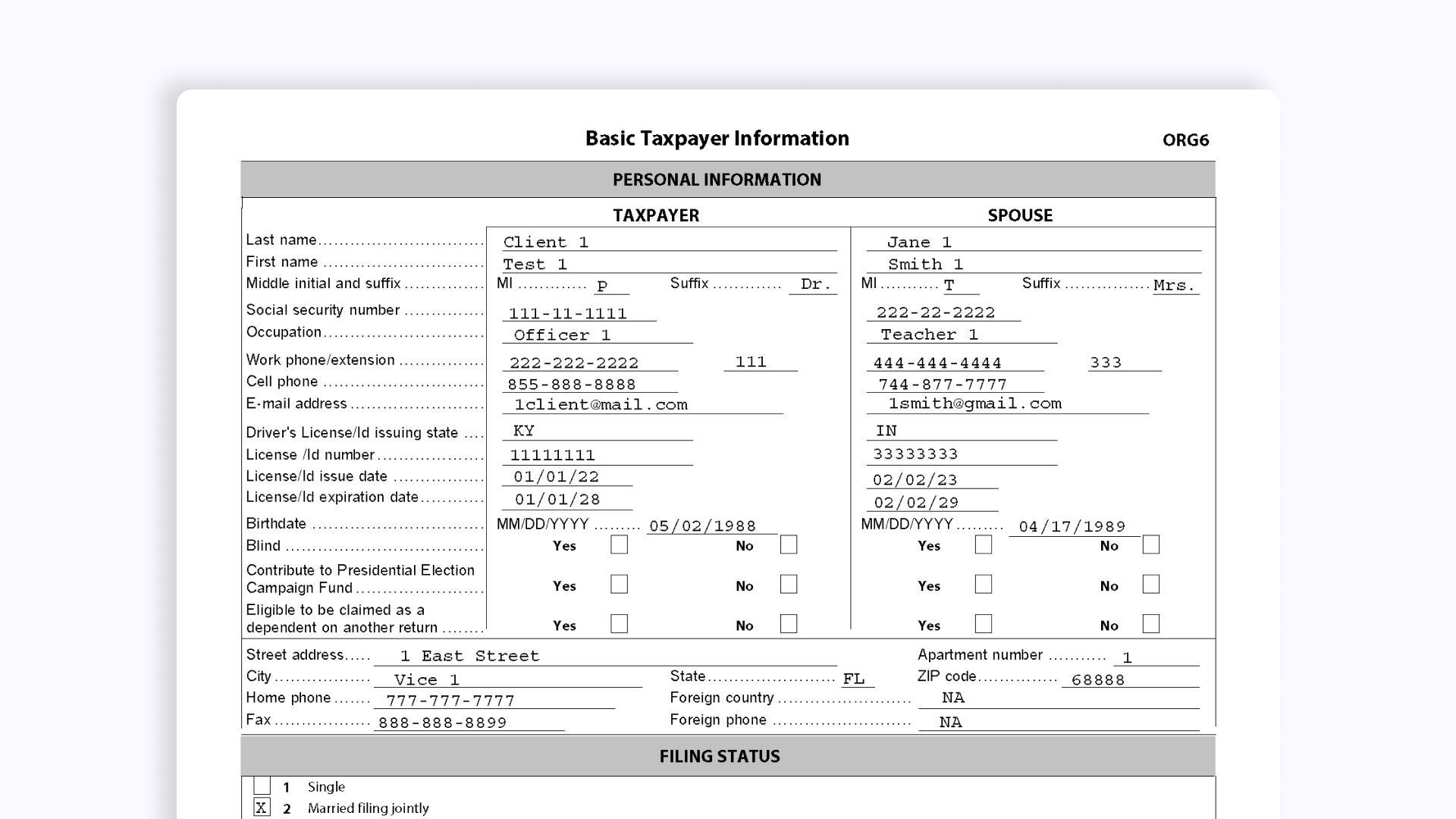
Налоговые документы представляют информацию в структурированном виде: внутри есть полями или "ключи" и связанные с соответствующие значения. Человек может легко интерпретировать такие документы.
Инструменты OCR умеют извлекать текст непосредственно из изображений, что позволяет составить представление о содержании документа, однако этого недостаточно, когда необходимы дальнейшие шаги в анализе документа: сопоставление пар ключ-значение и выгрузка данных в клиентские базы данных.
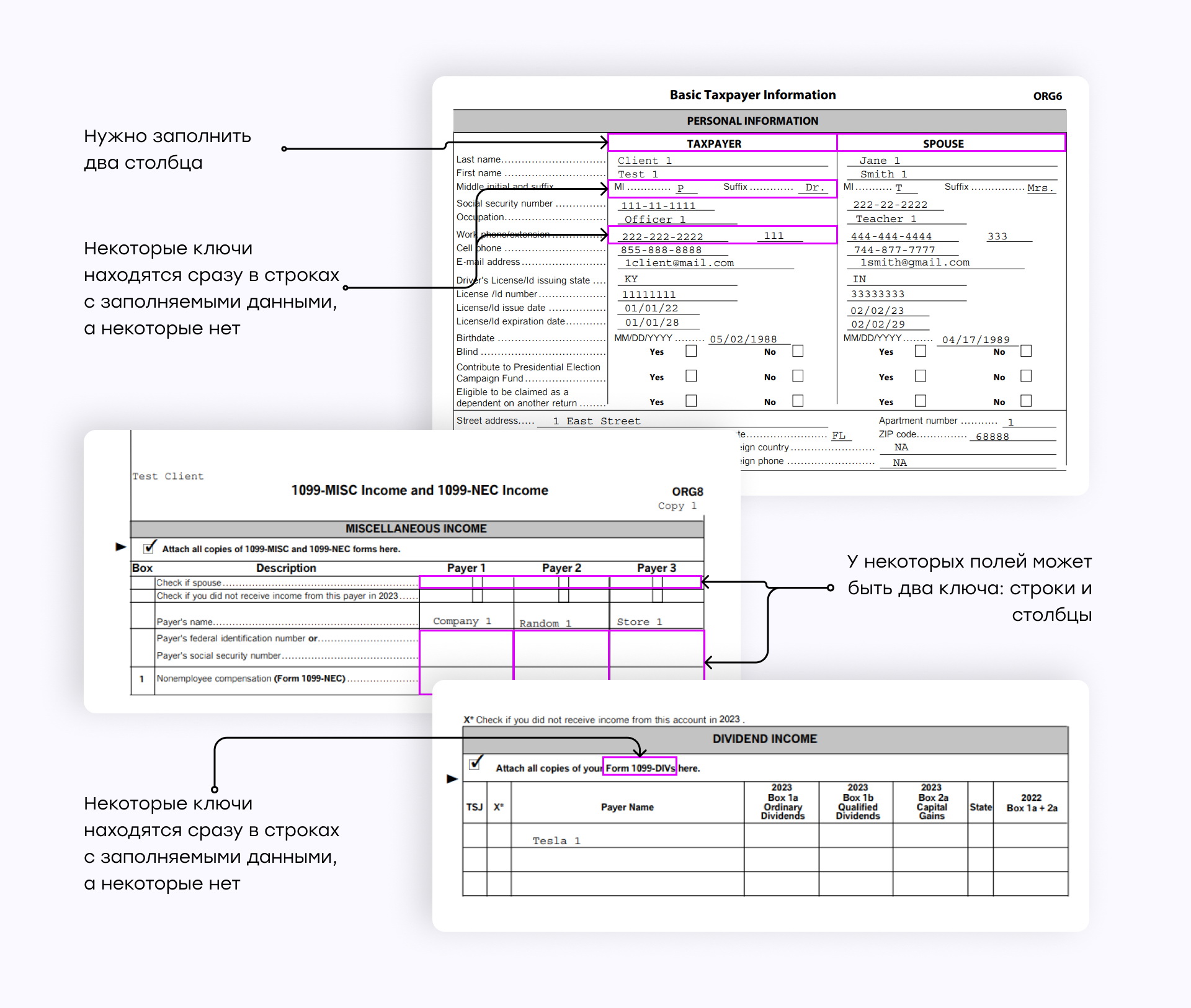
Сопоставление ключей и значений является наиболее сложным и труднореализуемым процессом. К примеру, налоговые формы в данном примере имеют сложную структуру. У некоторых значений нет соответствующих ключей. Другие же значения могут иметь несколько ключей из-за структуры таблицы, где метки строк и столбцов определяют поле, несмотря на их пространственное разделение на странице.
Соотнесение ключей со значениями предполагает субъективную интерпретацию макета страницы, пунктуации и стилистических признаков. Пары "ключ-значение" могут быть представлены вертикально или горизонтально, а ключи выделены различными способами, например двоеточиями или жирным шрифтом.
Более того, часть pdf-документов, с которыми работает бизнес, имеют возможность динамического заполнения полей. А значит, сервис извлечения данных должен уметь работать с заполняемыми полями. Это еще одно важное требование современного бизнеса.
Сравнение сервисов
Существует несколько готовых OCR решений, позволяющих извлекать пары ключ-значение из документа. К ним относятся AWS Textract и Azure Document Intelligence. Это лидеры рынка, которым большой бизнес отдает предпочтение.
Но данные сервисы имеют определенные ограничения, поэтому мы создали своё решение — Ripper Service, которое обладает более тонкой настройкой, и позволяет найти индивидуальный подход к каждому документу. Перейдём к сравнению.
AWS intelligent document processing

AWS Intelligent Document Processing — это набор сервисов машинного обучения, позволяющих автоматизировать обработку документов.
Платформа использует оптическое распознавание символов (OCR) и обработку естественного языка (NLP) для чтения и понимания документа и извлечения определенных терминов или слов.
AWS Intelligent Document Processing помогает сократить ручную работу и обнаружить в документах глубокий смысл, обеспечивая более быструю и точную обработку с высокой степенью достоверности. Вот некоторые ключевые особенности AWS Intelligent Document Processing:
- Готовые модели: AWS предлагает набор готовых моделей для обработки документов, включая Amazon Textract для извлечения текста и Amazon Comprehend для извлечения информации из текста в документах.
- Процессоры обработки документов: AWS Intelligent Document Processing может быть полностью развёрнута с использованием инфраструктуры как кода. А бессерверную инфраструктуру можно развернуть при помощи AWS Cloud Development Kit и организовать, используя визуальные сервисы рабочих процессов с низким кодом, такие как AWS Step Functions.
- Извлечение данных: AWS Intelligent Document Processing может извлекать печатный текст, почерк и данные из любого документа.
- Технология искусственного интеллекта: AWS Intelligent Document Processing использует ведущие в отрасли технологии машинного обучения, включая NLP-движки Amazon Textract и Amazon Comprehend, без необходимости привлечения штатных специалистов в области ML.
Amazon Textract — неотъемлемый компонент Amazon Web Services (AWS),именно о нём мы и будем говорить в разрезе анализа документов. Textract обладает некоторыми ограничениями:
- Pdf-файлы поддерживаются только асинхронными операциями; синхронные и асинхронные операции поддерживают файлы jpeg, png и tiff. Ограничения по размеру гораздо выше для асинхронных операций (500 МБ и 3 000 страниц для файлов pdf и tiff), чем для синхронных операций (10 МБ, 1 страница).
- Amazon Textract поддерживает до 15 запросов на страницу для синхронных операций и до 30 запросов на страницу для асинхронных операций.
- Невозможно классифицировать документы по типу документа (паспорт, налоговая декларация, форма 1040, расписание и т. д.)
- AWS Textract использует стандартную модель для извлечения данных из ваших конкретных форм. У вас нет возможности улучшить и доработать обобщенную модель для вашей конкретной формы или задачи.
- Не извлекает данные из заполняемых полей.
- Кириллица плохо воспринимается AWS Textract.
Чтобы инициировать асинхронные вызовы Textract, документы должны быть сначала загружены в S3 хранилище, т.к. прямая отправка в Textract невозможна. Если ваши данные уже хранятся в S3, это требование может не доставить заметных неудобств. Однако если ваши данные еще не хранятся в S3, этот шаг может занять значительное время.
Azure AI Document Intelligence
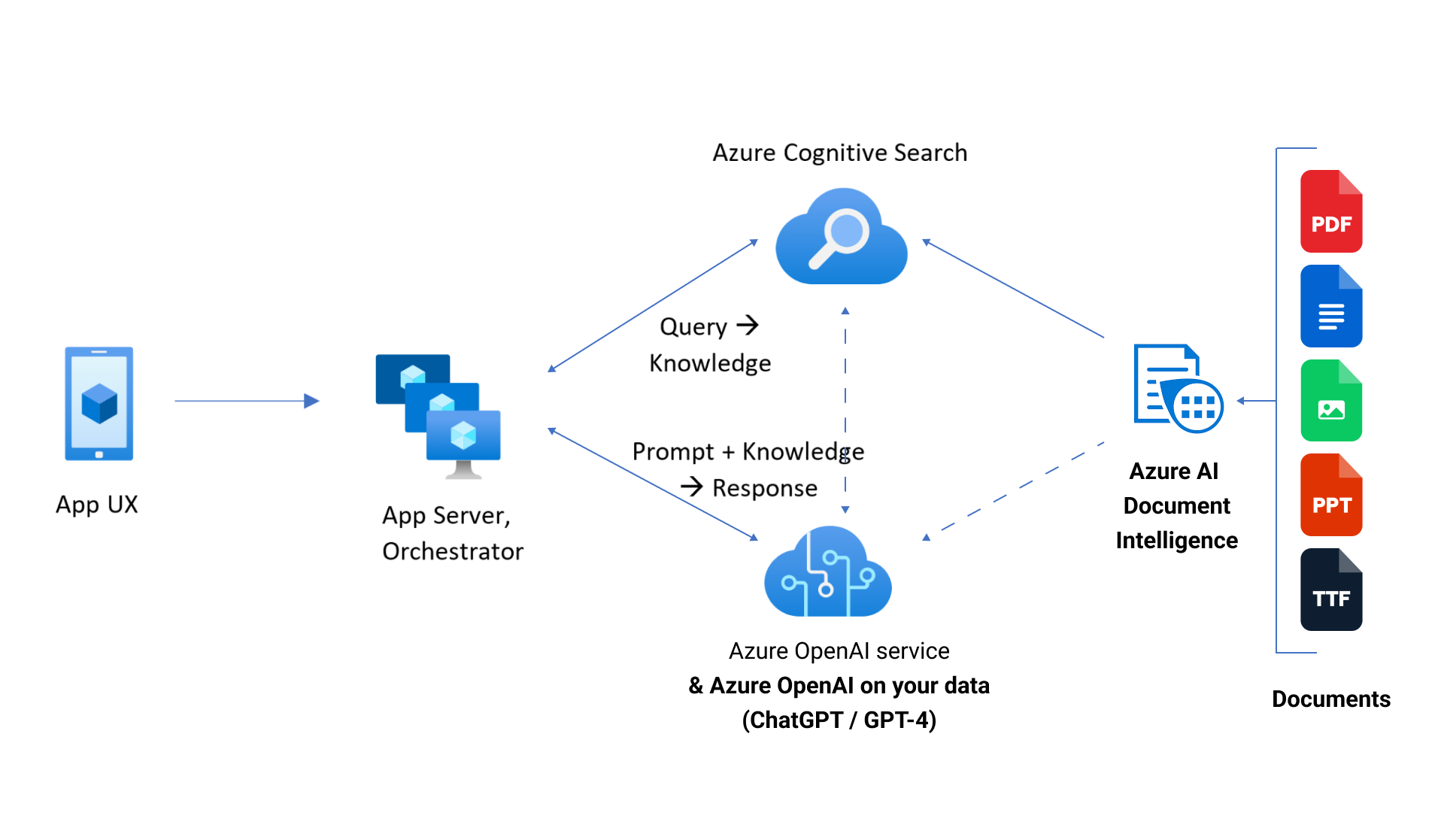
Azure AI Document Intelligence — это облачный сервис, который использует модели машинного обучения для извлечения текста, пар ключ-значение, таблиц и структур из документов.
Платформа может использоваться для автоматизации обработки данных в приложениях и рабочих процессах, а также необходима для совершенствования стратегий, основанных на данных, и расширения возможностей поиска по документам. Вот некоторые ключевые особенности Azure AI Document Intelligence:
- Готовые модели: Azure AI Document Intelligence предлагает набор готовых моделей для обработки документов, включая модель Read OCR для извлечения печатного и рукописного текста из PDF-документов и отсканированных изображений, а также модель Layout для извлечения страниц, таблиц и стилей.
- Пользовательские модели: Azure AI Document Intelligence позволяет обучать свои собственные модели, отвечающие конкретным бизнес-потребностям и сценариям использования. Пользователи могут размечать и обучать свои модели для автоматизации извлечения данных из структурированных, полуструктурированных и неструктурированных документов.
- Извлечение данных: Azure AI Document Intelligence может извлекать текст, пары ключ-значение, таблицы и структуры из различных типов документов, включая печатные и рукописные формы, PDF-файлы и изображения.
- Технология искусственного интеллекта: Azure AI Document Intelligence применяет передовое машинное обучение для извлечения текста, пар ключ-значение, таблиц и структур из документов. Для извлечения данных из документов платформа использует технологии оптического распознавания символов (OCR) и понимания документов.
- Azure Document Intelligence поддерживает кириллицу.
Работу с сервисом можно начать с готовых моделей или создать собственные модели, адаптированные к вашим документам, локально или в облаке, используя AI Document Intelligence Studio или SDK.
Чтобы извлечь данные с высоким качеством, необходимо обучить собственную модель с помощью инструментария Azure Document Intelligence. Кстати, обучение пользовательских моделей всегда бесплатно.
AI Document Intelligence обладает некоторыми ограничениями:
- У Microsoft есть готовая модель для извлечения общих форм, но качество работы этой модели мы находим сомнительным для форм, не входящих в список готовых. Если вы хотите получить данные формы из документа, который не является англоязычной квитанцией, счетом-фактурой, удостоверением личности или визитной карточкой, то придется обучить свою собственную модель.
- Готового сервиса общего назначения для извлечения пар ключ-значение не существует.
- Обучение пользовательской нейронной модели: можно обучить до 20 шт. в месяц.
- Для PDF и TIFF можно обработать до 2000 страниц (при подписке на бесплатный уровень обрабатываются только первые две страницы).
- Не извлекает данные из заполняемых полей.
Ripper Service от Технологики
Ripper Service — это сервис для обработки и извлечения данных из документов. Сервис принимает на вход pdf-документ, а на выходе возвращает JSON-файл с извлеченными значениями и координатами границ целевых полей в формате ключ-значение:

Философия Ripper Service заключается в индивидуальном подходе к каждой форме. Возможности Ripper Service позволяют тонко настраивать и индивидуально работать с любым сложным документом, а также работать с заполняемыми полями документа и с документами на кириллице. Это достигается за счёт использования следующего технологического стека:
- OpenCV — библиотека функций программирования преимущественно для компьютерного зрения в реальном времени.
- Docotic.Pdf — SDK позволяет разработчикам составлять, отображать, захватывать, аннотировать, очищать, редактировать и печатать PDF-документы и изображения.
- AWS Textract Detect Document Text API (опционально) — технология OCR для извлечения текста. В случае необходимости наше решение позволяет интегрировать и сторонние инструменты. Например, в случае если мы имеем дело с pdf без текстового слоя, для распознавания символов мы предпочитаем использовать OCR решение от AWS. Распознавание текста — это малая, но важная часть работы с документами, а AWS предоставляет качественный инструмент для решения данной задачи.
Извлечение данных из форм в Ripper Service происходит в несколько этапов:
- Используя OpenCV, мы находим все геометрические объекты (вертикальные и горизонтальные линии, ячейки) для данной страницы.
- Извлекаем текст со страницы с координатами ограничительных рамок с помощью Docotic.Pdf (если документ содержит текстовый слой) или OCR (если текстового слоя нет)
- Определяем тип документа, используя информацию из 1 и 2 шага (что это: налоговая декларация, ваучер, документ, удостоверяющий личность, платежная квитанция и т. д.).
- Составляем карту и извлекаем целевые поля, используя относительные координаты слов и геометрических объектов на странице (или в таблицах).
Ограничения Ripper Service:
- Для каждой формы требуется разработка собственного детектора.
- Если документ не содержит текстового слоя, то сервису необходимо использовать технологию OCR, предоставляемую AWS Textract (или Azure Document Intelligence). Это приводит к соответствующим квотам и ограничениям.
Заинтересовались Ripper Service?
Напишите нам, чтобы обсудить применение Ripper Service на ваших документах!
Сравнение производительности сервисов
Для сравнения эффективности работы всех трех сервисов был взят налоговый документ из ProSeries Tax organizer.
| Ripper Service | AWS Textract | Azure Document Intelligence | |
|---|---|---|---|
| Одностраничный документ | 8 секунд | 53 секунды | 13 секунд |
| Документ из 66 страниц | 18 секунд | 99 секунд | 47 секунд |
Как видно из анализа производительности, Ripper Service показывает самые быстрые результаты, потому что не является облачным решением.
Результаты извлечения пар ключ-значение из форм
Azure Document Intelligence
Общая модель Azure Document Intelligence пропустила очень много пар ключ-значение и сделала много ошибок в найденных полях в разделе "Личная информация".
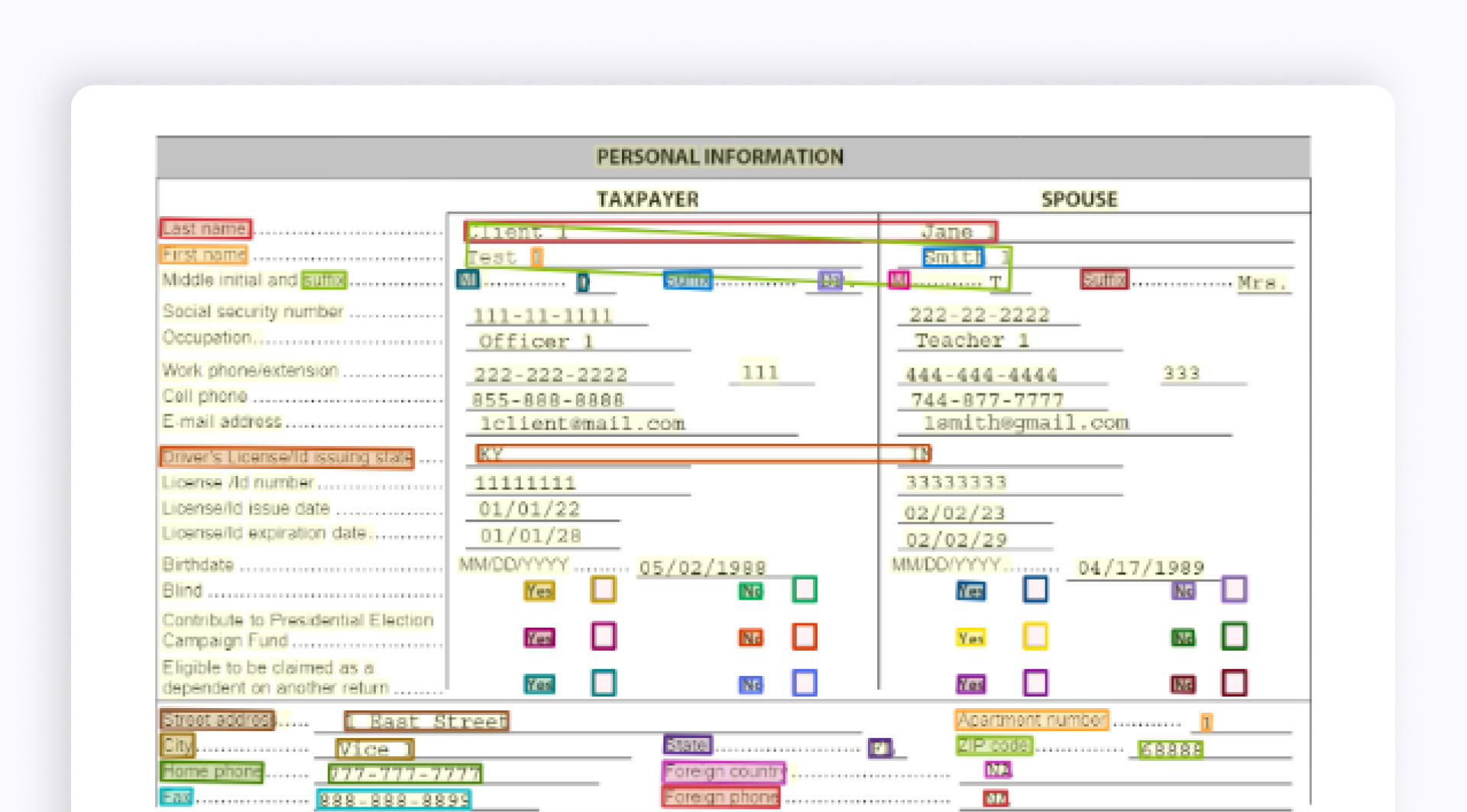
Если мы распознаем этот раздел как таблицу, общая модель также будет допускать ошибки в структуре таблицы. Поэтому вам потребуется некоторое время, чтобы разобрать и обработать эту таблицу. Но таблица может не иметь фиксированной структуры для каждого нового запроса. Поэтому ее трудно адаптировать к вашему алгоритму:
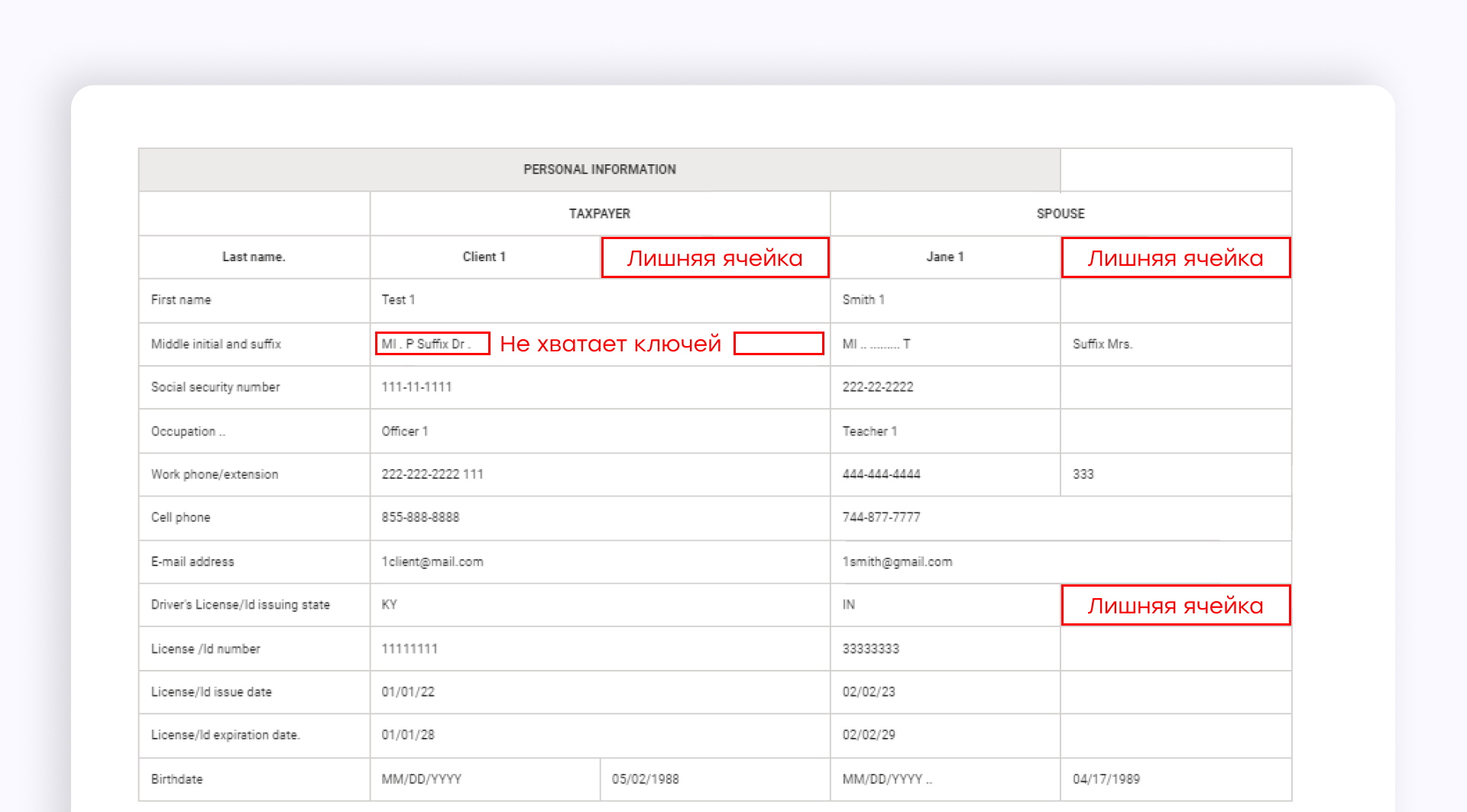
Другой вариант — обучить собственную модель для специальной формы. Azure Document Intelligence как раз предоставляет такую возможность, поэтому она может решить описанные выше проблемы.
AWS Textract (формы + таблицы)
AWS Textract извлекает пары ключ-значение немного лучше, чем общая модель Azure, но все равно допускает много ошибок: много отсутствующих ключей и значений (отсутствующие значения, особенно в столбце "Spouse").
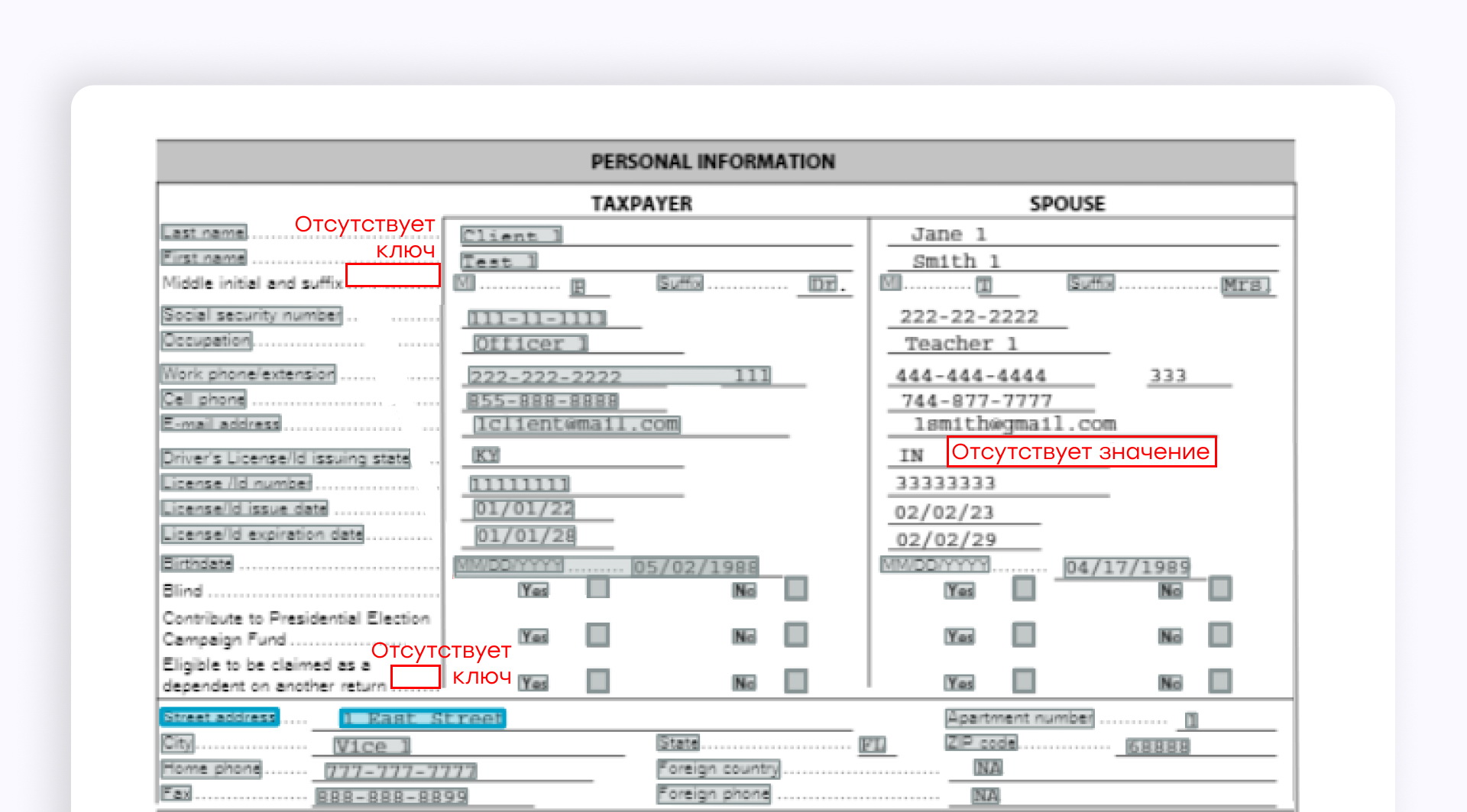
Если мы распознаем этот раздел как таблицу с помощью AWS Textract, некоторые из полей с несколькими ключами или ключами с несколькими значениями будут объединены в одну ячейку. Таким образом, структура документа будет нарушена.
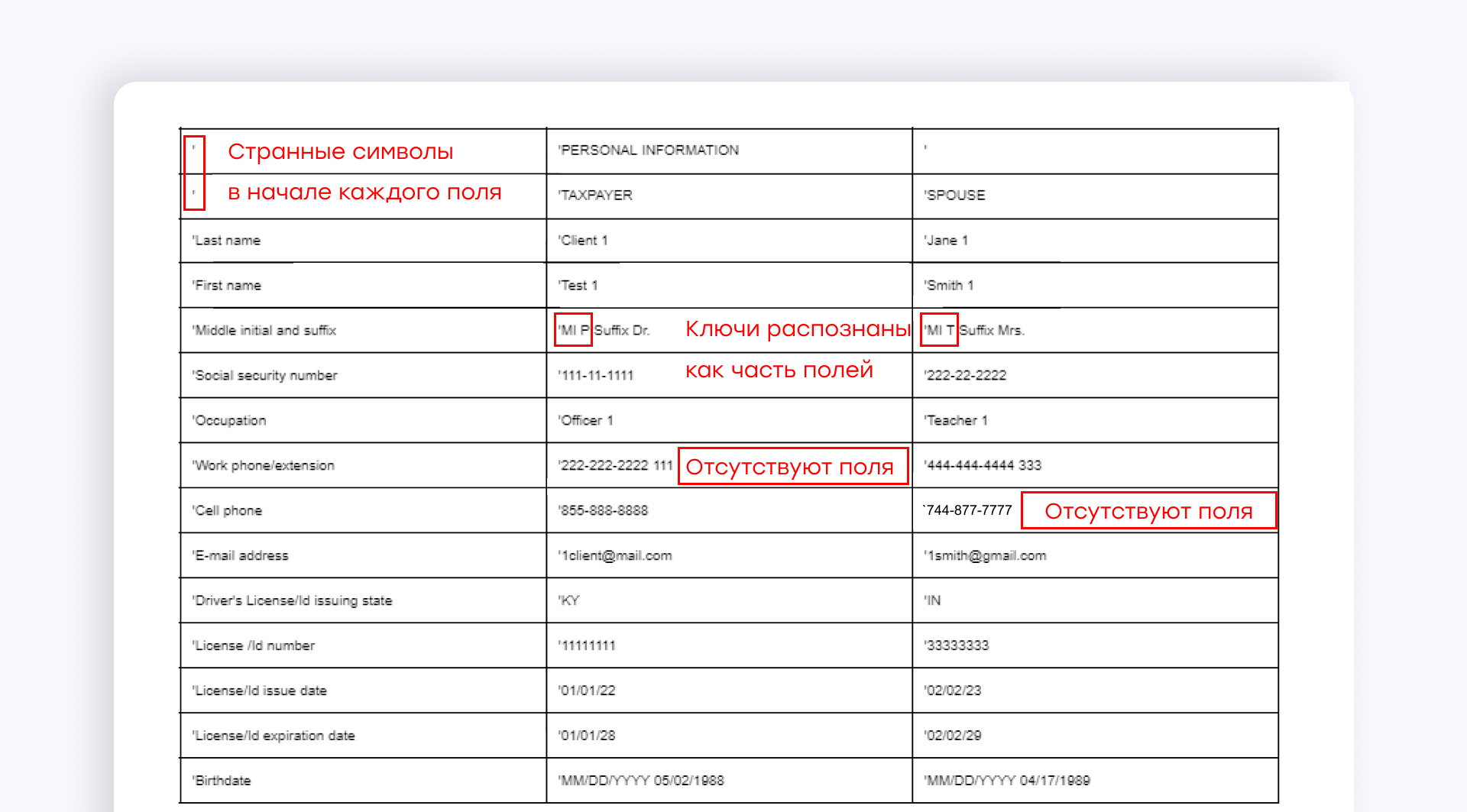
Кроме того, в отличие от Azure, в AWS Textract нет возможности обучить свою собственную модель или настроить модели AWS Textract под свои нужды.
Ripper Service
Решение Ripper Service позволяет точно настроить детекторы для каждой отдельной формы. А значит, результат будет лучше, чем у обобщенных моделей Azure и AWS.

Все ключи и значения были обнаружены и извлечены из описывающих их прямоугольников, которые могут пригодиться для дальнейшего маппинга в пользовательском интерфейсе. Но решение данной задачи потребовало дополнительного анализа структуры документа и реализации специального детектора для этого раздела.
Цены на сервисы
Рассмотрим различные тарифные планы сервисов интеллектуальной обработки документов в зависимости от количества страниц (10 тысяч, 100 тысяч, 1 миллион).
Отметим, что любая цена не включает настройку под конкретные формы и стоимость хостинга/инфраструктуры. Общая стоимость зависит от количества форм, нагрузки, пиковой нагрузки, развертывания облака/внутренней инфраструктуры и т. д.
| Цена указана за 1 тыс. стр. | Тарифный план 1: Обработка 10 тысяч страниц | Тарифный план 2: Обработка 100 тысяч страниц | Тарифный план 3: Обработка более 1 млн. страниц |
|---|---|---|---|
| Ripper Service (Single Server or Single Application) | $99.50 | $9.95 | $0.99 или меньше |
| Ripper Service (Single Server or Single Application + OCR) | $101.00 | $11.45 | $2.49-$1.50 / $1.49-$0.50* |
| Ripper Service (Scalable solution) | $329.50 | $32.95 | $3.29 или меньше |
| Ripper Service (Scalable solution + OCR) | $331.00 | $34.45 | $4.79-$1.50 / $3.79-$0.50* |
| AWS Textract | $65.00 | $65.00 | $65.00 / $50.00* |
| Azure Document Intelligence | $50.00 | $50.00 | $50.00 |
* Более 1 миллиона страниц в месяц.
Выводы
Облачные сервисы с готовыми решениями комплексной интеллектуальной обработки документов относительно дороги (5 — 6,5 центов за страницу). Внедрение ИИ-обработки документов может быть неоправданно экономически. Более того, для использования данных сервисов необходимо иметь возможность оплачивать зарубежный сервис.
В то же время облачные сервисы предоставляют качественные и недорогие OCR инструменты, которые позволяют извлекать неструктурированный текст. Но они всё ещё не имеют возможности извлекать данные из интерактивных документов с заполняемыми полями. А такие документы часто используются бизнесом, а именно в судебной системе и налоговых и бухгалтерских сферах.
Также проблему представляют кириллические документы. Если Azure Document Intelligence ещё хоть как-то поддерживает кириллицу, то AWS Textract — нет.
Хотите увидеть аналитику по русскоязычным сервисам?
Напишите нам, если вам интересно сравнение с сервисами Yandex Vision, VK Cloud Vision и Компьютерное зрение от СберCloud.
Azure Document Intelligence имеет достаточно быстрый отклик для одностраничного документа и хорошо масштабируется при увеличении количества страниц. Использование общей модели показало низкое качество распознавания пар ключ-значение и таблиц.
Однако есть возможность дополнительно обучить собственную модель для конкретной формы, которая работает достаточно хорошо. Но эта возможность имеет некоторые ограничения по количеству моделей и обучающих образцов. Существуют также предварительно обученные модели для не очень большого списка распространенных форм.
AWS Textract имеет довольно медленный асинхронный отклик, что ставит под сомнение его использование для обработки документов в реальном времени. Кроме того, точность разбора форм AWS Textract была низкой в некоторых разделах налогового документа, который мы анализировали. В AWS Textract нет возможности обучить пользовательскую модель или как-то улучшить качество общей модели для конкретной формы.
Ripper Service работает довольно быстро и может использоваться для обработки как одностраничных, так и многостраничных документов в режиме реального времени. Качество извлечения пар ключ-значение и таблиц очень высокое, но требует индивидуальной настройки для каждой конкретной формы.
Стоимость распознавания одной страницы значительно ниже по сравнению с облачными сервисами. Кроме того, Ripper Service может работать с интерактивными документами с заполняемыми полями, а также отлично понимает кириллические тексты. Однако для этого необходимо использовать высококачественный OCR (из AWS Textract OCR или Azure Document Intelligence Read), если исходный документ не имеет текстового слоя.