Внедрение поисковой системы в крупное CRM-решение: наш опыт
О проекте
Один из наших длительных проектов - это крупное многопользовательское SaaS-решение (CRM-система) основанное на микросервисной архитектуре и развернутое в облаке Azure. Изначально это был MVP, где все части (сервисы, базы данных и т. д.) располагались на одной виртуальной машине. Со временем проект вырос в облачное распределенное решение с множеством веб- и мобильных клиентов.
В этой статье мы расскажем, как решили одну из проблем, с которой столкнулись в процессе разработки.
Проблема
На тот момент проект включал около 12-14 сервисов, каждый из которых имел собственную базу данных в Azure SQL. Однако большинство сложных и критичных поисков осуществлялось по основной базе данных, в которой хранилось огромное количество информации о кандидатах (принятых, отклонённых, с которыми ведётся работа) по всем арендаторам.
CRM-решение было гибким и позволяло настраивать свойства кандидатов и множество связанных с ними данных, таких как история взаимодействия, профессиональные навыки и т. д. Поиск внутри приложения позволял задавать свои критерии фильтрации с большим количеством различных условий и переменных.
Хотя эта функция работала хорошо большую часть времени, всё же возникали проблемы из-за других факторов:
- Поддержка импорта большого количества кандидатов из внешних систем.
- Интеграция с несколькими внешними источниками кандидатов (данные из которых автоматически подтягивались в основную БД).
- Периодическая массовая обработка данных и обновление записей в таблицах, являвшихся основным источником для результатов поиска.
- Необходимость расширения поиска для включения фильтрации на основе данных в другой БД (история взаимодействия).
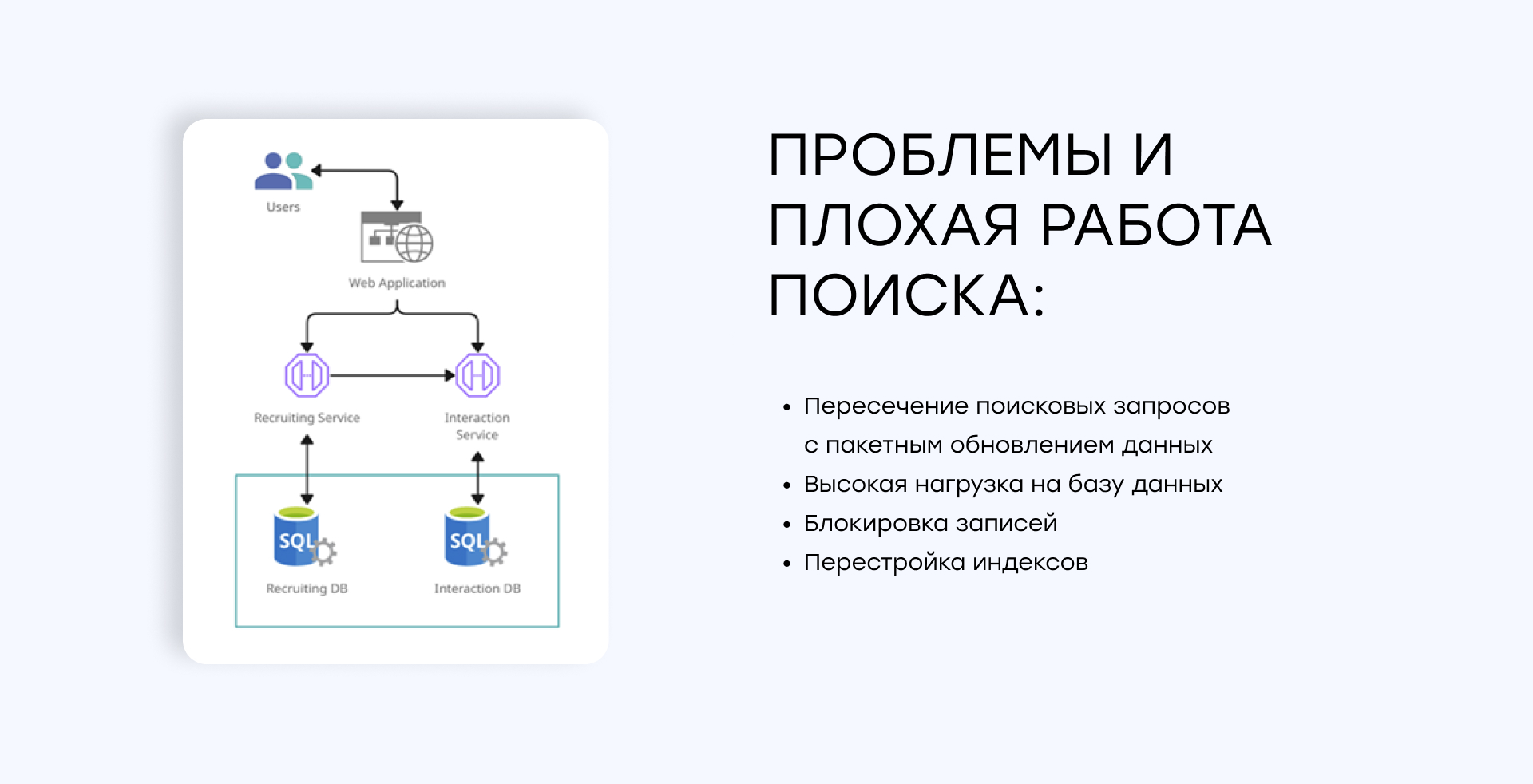
Всё это приводило к пересечению поисковых запросов с пакетным обновлением данных, высокой нагрузкой на базу данных, блокировками записей и перестройкой индексов, что ухудшало производительность поиска.
Анализ и Решение
Сервис Search Engine
Решением стала разработка Search Engine - отдельного сервиса для эффективной реализации поиска.
Первым шагом было решено вынести функционал поиска в новый сервис, развернутый в собственном Azure App Service Plan. Это позволило выделить больше памяти и процессорных ресурсов и масштабировать их независимо. Важно, что App Service Plan также поддерживает масштабирование и переменное количество экземпляров сервиса, что положительно сказалось на надёжности и производительности критически важных функций.
Кроме того, мы внедрили API-шлюз, который скрыл за собой несколько сервисов и обеспечил возможность плавного переключения между основным сервисом рекрутинга и новым сервисом поисковой системы.
Источник данных

Другой сложной задачей было избежать снижения производительности поиска при массовых обновлениях в основной БД. Мы рассмотрели несколько подходов:
- Elasticsearch
- Azure SQL с SQL Data Sync
- High Availability Read-only Replica (Высокодоступная реплика только для чтения)
- Geo-replication Azure SQL
Elasticsearch
Elasticsearch - отличное решение для мощных поисковых функций, но в нашем случае оно не подошло из-за необходимости частого обновления данных и перестройки индексов.
Основная проблема заключалась в том, что наша база данных допускала и поддерживала единичные и массовые обновления данных и кастомизацию. Это означало, что для внесения изменений потребовалось бы переписывать большие объемы данных в Elasticsearch и часто перестраивать индексы.
Кроме того, это означало бы, что нам придется разрабатывать и поддерживать мост данных между двумя базами данных.
SQL Data Sync в Azure
Идея синхронизации баз данных выглядела перспективно, но инструмент имеет ограничения и не поддерживает некоторые типы данных. Поэтому мы были вынуждены отказаться от него.
High Availability Read-only Replica
Рекомендуемый подход от Microsoft - использовать архитектуру High Availability с первичной БД для чтения и записи, и одной или несколькими вторичными репликами только для чтения.
Но эта функция поддерживается только на уровнях Premium и Business Critical в Azure SQL, что увеличило бы расходы. Поэтому для нашего клиента это решение не подошло.
Нужно облачное решение?
У нас большой опыт разработки облачных решений на AWS и Azure.
Geo-replication Azure DB
Geo-replication - оказалось единственным подходящим для нас решением. Функция Geo-replication позволила реализовать подход read-scale out, зарезервировав дополнительный Azure SQL Server на котором была развернута Geo-реплика основной базы данных.
Внешний источник данных
Еще одной задачей была необходимость поддержки кросс-запросов к базе данных. Поисковые запросы могли содержать условия, направленные к данным в основной БД, но также и дополнительные условия, которые должны были быть адресованы другой базе (в нашем случае БД с историей взаимодействия).
Первоначальная реализация включала в себя взаимодействие между двумя сервисами. Требовалось сформировать два подрезультата и собрать их в итоговый.
В качестве решения задачи мы использовали функции внешних источников данных и Cross-DB запросов. Но поскольку мы стали обращаться с поисковыми запросами к новому сервису, который работает с репликой, то было решено реализовать следующий подход:
- Мы настроили новый Azure SQL Server с репликами обеих баз данных.
- Добавили ссылку на реплику БД с историей взаимодействия в основную БД (не в реплику, а в мастер копию доступную для записи и чтения).
- В результате в реплике основной БД появилась ссылка на реплику БД с историей взаимодействия.
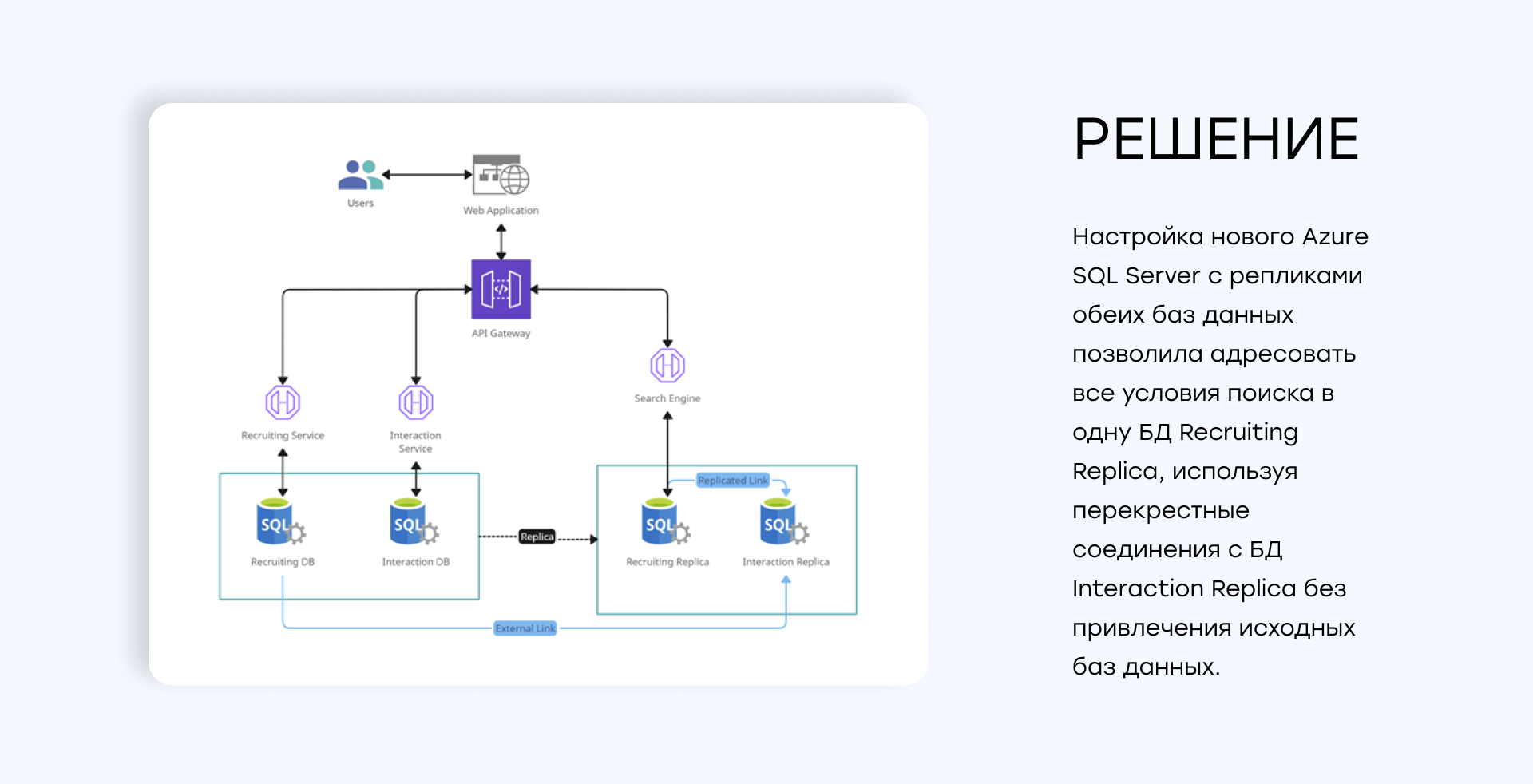
Настройка нового Azure SQL Server с репликами обеих баз данных позволило адресовать все условия поиска в одну Базу Данных, которая использовала перекрестные запросы ко второй реплике, не привлекая к поиску ни одну из исходных баз данных.
Результаты
Реализованный подход позволил:
- Разделить запросы на чтение и запись между двумя базами данных. Read-only реплики можно настраивать и масштабировать отдельно и, соответственно, не обязательно было выделять им много ресурсов.
- Избежать затрат времени на создание и интеграцию отдельного кластера (Elastic).
- Удержать расходы клиента на облачную инфраструктуру на приемлемом уровне.
- Значительно повысить эффективность, стабильность и надёжность критически важной функции поиска.
API и реализация поиска при этом остались прозрачной для всей команды разработчиков, что также немаловажно для поддержания высокого уровня качества и скорости процесса разработки.
Этот опыт демонстрирует, как правильный выбор архитектурных решений может значительно улучшить производительность и стабильность систем, обеспечивая эффективное масштабирование и снижение затрат.