Сервис учёта успеваемости для ВУЗов на основе компьютерного зрения

Бизнес логика
Заказчик - один из ВУЗов, который задумался о создании электронного сервиса, автоматизирующего процесс тестирования учащихся по различным дисциплинам. Этот сервис также должен также хранить экзаменационную историю, и предоставлять преподавателям доступ к отметкам и их динамике.
Поскольку тестовые бланки заполняются студентами от руки и в систему должны попадать в виде сканов, необходимо решить проблему хранения большого количества отсканированных бланков.
Когда заказчик “обкатает” разработанную систему, данный сервис станет SaaS-решением и будет как услуга поставляться в другие ВУЗы.
Решение
Решение поставленной задачи мы разбили на несколько этапов:
- Разработка бланков
- Непосредственно тестирование
- Распознавание бланков и наполнение электронного дневника
- Рекомендации по улучшению успеваемости
Разработка бланков
Чтобы наша будущая CV-модель знала, в каких областях искать рукописные ответы студентов, мы разработали тестовый бланк. Для генерации тестовых бланков мы воспользовались базами данных, в которых хранятся данные о ВУЗе, студентах и учебных группах.
На основе этих данных мы генерировали QR код, который связывает тестовый бланк с конкретным студентом в базе данных. Помимо QR кода на каждом бланке присутствуют такие данные как ФИО студента, номер группы и потока, предмет, поле для даты, поле для тестовых ответов и баллов, поле для подписи экзаменатора.

Тестирование студентов
На данном этапе преподаватель распечатывает бланки, которые сгенерировала наша система, раздает студентам для тестирования, затем собирает и сканирует.
Распознавание бланков и наполнение базы данных успеваемости
Хранить сканы тестовых бланков по каждому студенту не представляется возможным, поскольку для этого требуются огромные хранилища данных. Поэтому заполненные от руки бланки переводятся в цифровой вид при помощи технологий компьютерного зрения.
На входе наша система получает большой файл с отсканированными подряд бланками. Система на основе QR кодов находит бланк каждого студента, а затем происходит распознавание рукописных текстов.
Именно распознавание компьютерным зрением и является основной сложностью проекта. В этом процессе нам помогли два момента: во-первых, студенты пишут ответы в конкретных ячейках, расположение которых не меняется, а во-вторых, студенты обязаны использовать печатные буквы, которые не так сильно различаются, как рукописный текст, несмотря на отличия в почерке.
Для обучения CV модели мы использовали большой датасет, который содержит множество разных примеров того, как может выглядеть тот или иной рукописный символ.

После того как бланки были распознаны и сопоставлены с эталонными ответами по экзамену, каждый студент получает оценку, которая заносится в систему успеваемости.
В эту систему доступ имеют и студенты и преподаватели. Но если студенты могут просматривать только свой профайл, то преподаватели могут просматривать успеваемость всех своих групп и всех своих студентов по отдельности.
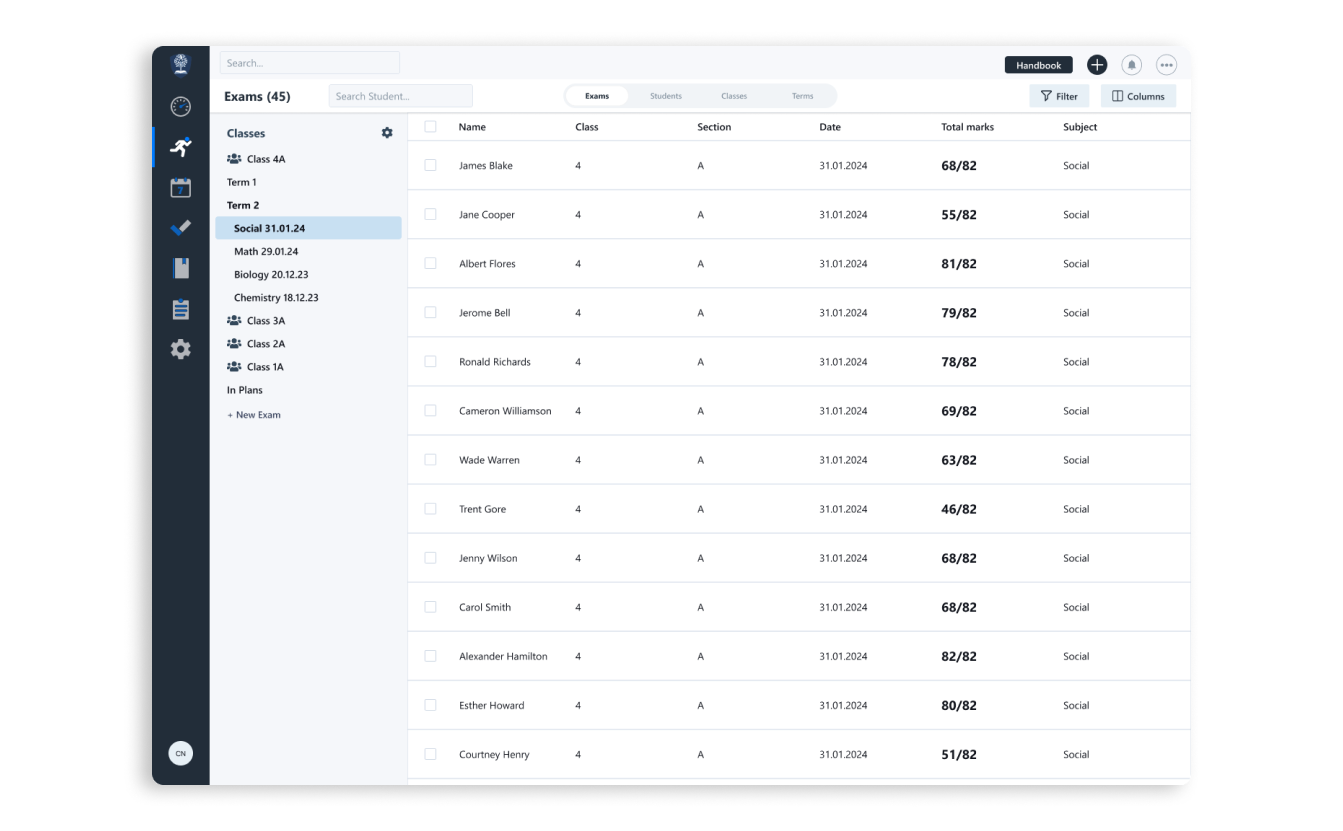
Система рекомендаций
Поскольку каждый студент имеет личный аккаунт в системе успеваемости, мы интегрировали в сервис ChatGPT, который на основе нашего промпта умеет давать рекомендации по улучшению успеваемости.
ChatGPT знает программу курса, а также знает, о чем каждое тестирование. И после того как нейросеть проанализирует ответы на вопросы, сопоставит их с темами курса, она может предложить студенту рекомендации по восполнению пробелов в знаниях.
Результаты
Данные по каждому студенту по каждому экзамену хранятся в нашем электронном сервисе по успеваемости. Преподаватель может посмотреть любые срезы: по студенту, по группе, по потоку через интерфейс сервиса.
Также через данный сервис происходит подготовка тестовых бланков к новому тестированию и выдача рекомендаций по улучшению успеваемости.
Когда система пройдет определенное тестирование преподавателями заказчика, клиент планирует превратить данный сервис в услугу для других ВУЗов, т.е. в SaaS-решение.