Извлечение характеристик из сложных инженерных чертежей с помощью ИИ
Инженерные документы чаще всего обрабатываются вручную из-за их сложной структуры и отсутствия стандартизации. Из-за их сложности использование готовых ИИ-решений для извлечения данных не всегда дает удовлетворительные результаты, особенно если чертежи содержат повернутые элементы.
В этой статье мы рассказываем о своем опыте разработки системы искусственного интеллекта для обработки сложных инженерных чертежей и о том, как мы решили проблему обнаружения аннотаций к геометрическим размерам и допускам, расположенных под углом.
ИИ для обработки неструктурированных данных
Извлечение неструктурированных данных представляет собой важнейший рубеж в сфере управления информацией, предлагая организациям возможность извлечь ценные сведения из документов.
В отличие от структурированных данных, которые придерживаются заранее определенных форматов или схем, неструктурированные данные не имеют чёткой организации, что делает их сложными для извлечения информации - сотруднику приходится вручную искать нужную информацию на всех страницах документа.
Хотите заказать решение для обработки чертежей?
Напишите нам!
И мы разработаем решение для обработки ваших документов!
Инженерные чертежи - классический пример неструктурированного документа: несмотря на соблюдение ряда строгих стандартов проектирования, сами чертежи значительно отличаются друг от друга, не имеют жесткой структуры и включают в себя смесь текста, специальных символов и геометрических фигур, что затрудняет извлечение необходимой информации вручную.
Используя методы извлечения информации, основанные на искусственном интеллекте, можно легко анализировать инженерные чертежи, извлекая необходимые детали, такие как аннотации к геометрическим размерам и допускам, блоки заголовков, меры и т. д.
Проблема готовых решений для обработки инженерной документации
Несмотря на обилие решений для обработки документов, в том числе и тех, которые предназначены специально для обработки инженерных чертежей, потребность в индивидуальных решениях по-прежнему велика, поскольку готовые системы часто не могут справиться даже с незначительными отклонениями от стандартной схемы инженерных чертежей.
Одной из основных проблем, с которыми сталкиваются готовые системы, являются элементы, расположенные по диагонали - аннотации к геометрическим размерам и допускам.
Решения для обработки документов часто испытывают трудности с обработкой диагонального текста, не говоря уже о распознавании специальных символов. Инженерные чертежи часто содержат пересекающиеся линии и элементы, что еще больше усугубляет проблему.
Извлечение характеристик из инженерных чертежей: наш подход
Извлечение характеристик инженерных чертежей чаще всего включает в себя обнаружение аннотаций геометрических размеров и допусков (GD&T), которые включают в себя как текст, так и специальные символы.
Учитывая их переменное позиционирование, возможность поворот, и множество типов данных, процесс обнаружения и извлечения аннотаций GD&T включает несколько этапов. Рассмотрим каждый из них.
Шаг 1. Определение положения GD&T
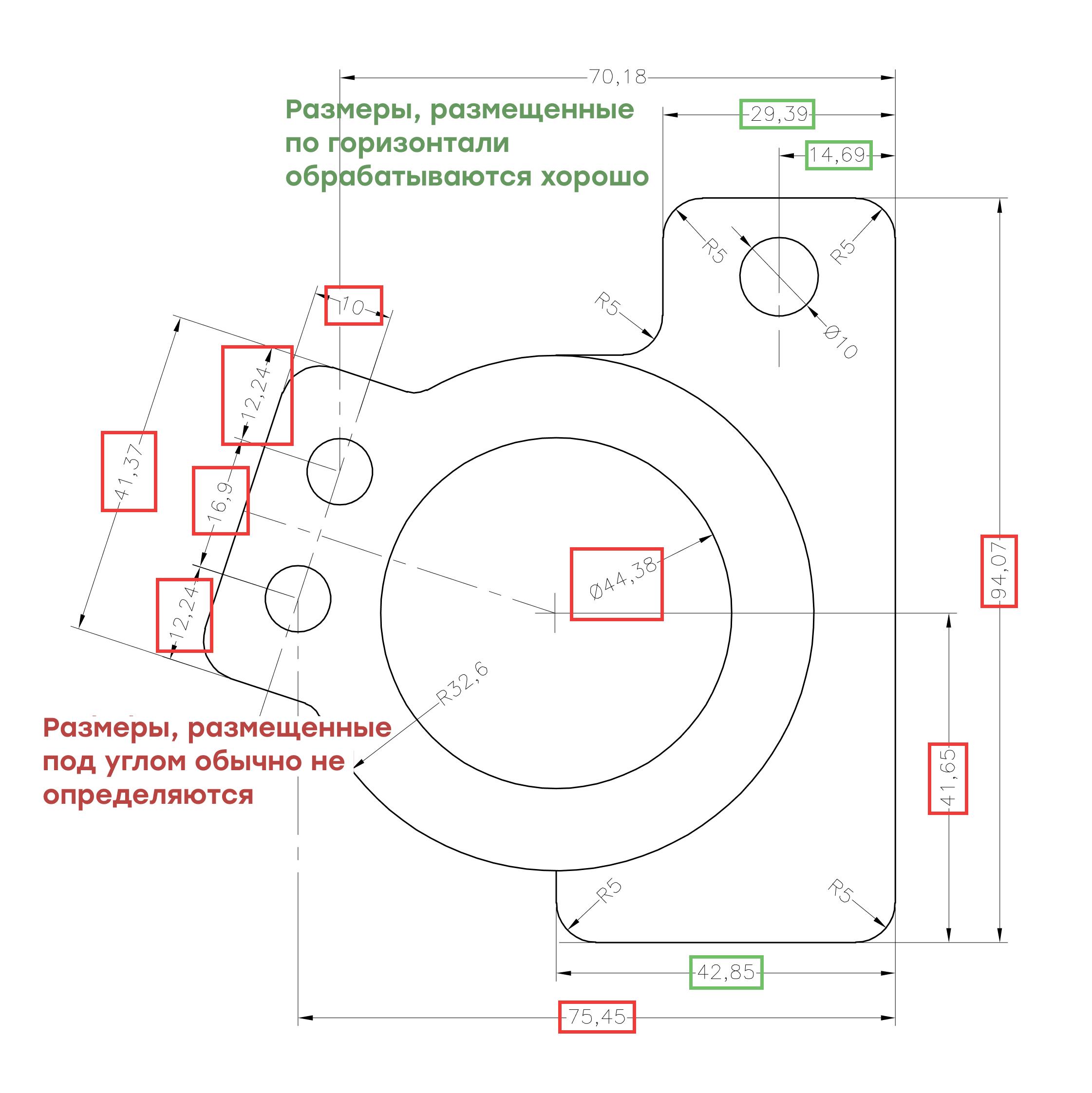
Первый шаг - обнаружение аннотаций геометрических размеров и допусков на чертеже с помощью OpenCV. Алгоритмы компьютерного зрения можно обучить обнаруживать объекты независимо от их положения и угла наклона.
Имея опыт решения подобных задач, как, например, в нашем проекте по распознаванию архитектурных чертежей, мы имеем прочную основу для создания подобных систем, что мы и сделали для нашего клиента:
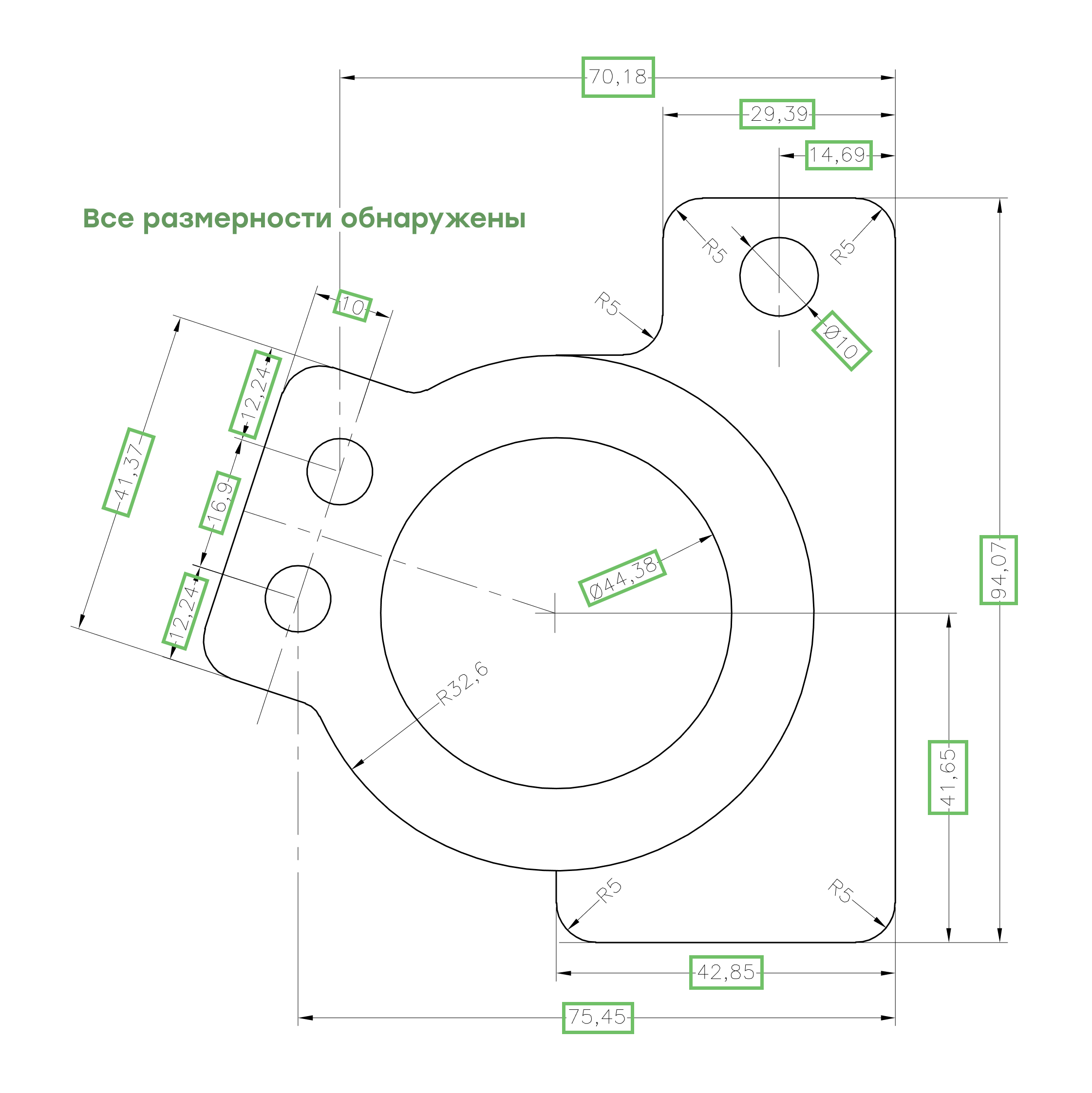
Шаг 2: Определение угла поворота
Для каждой аннотации GD&T мы вычисляем угол поворота, который используется для поворота аннотации, чтобы сделать ее горизонтальной и вырезать из чертежа для дальнейшей обработки:
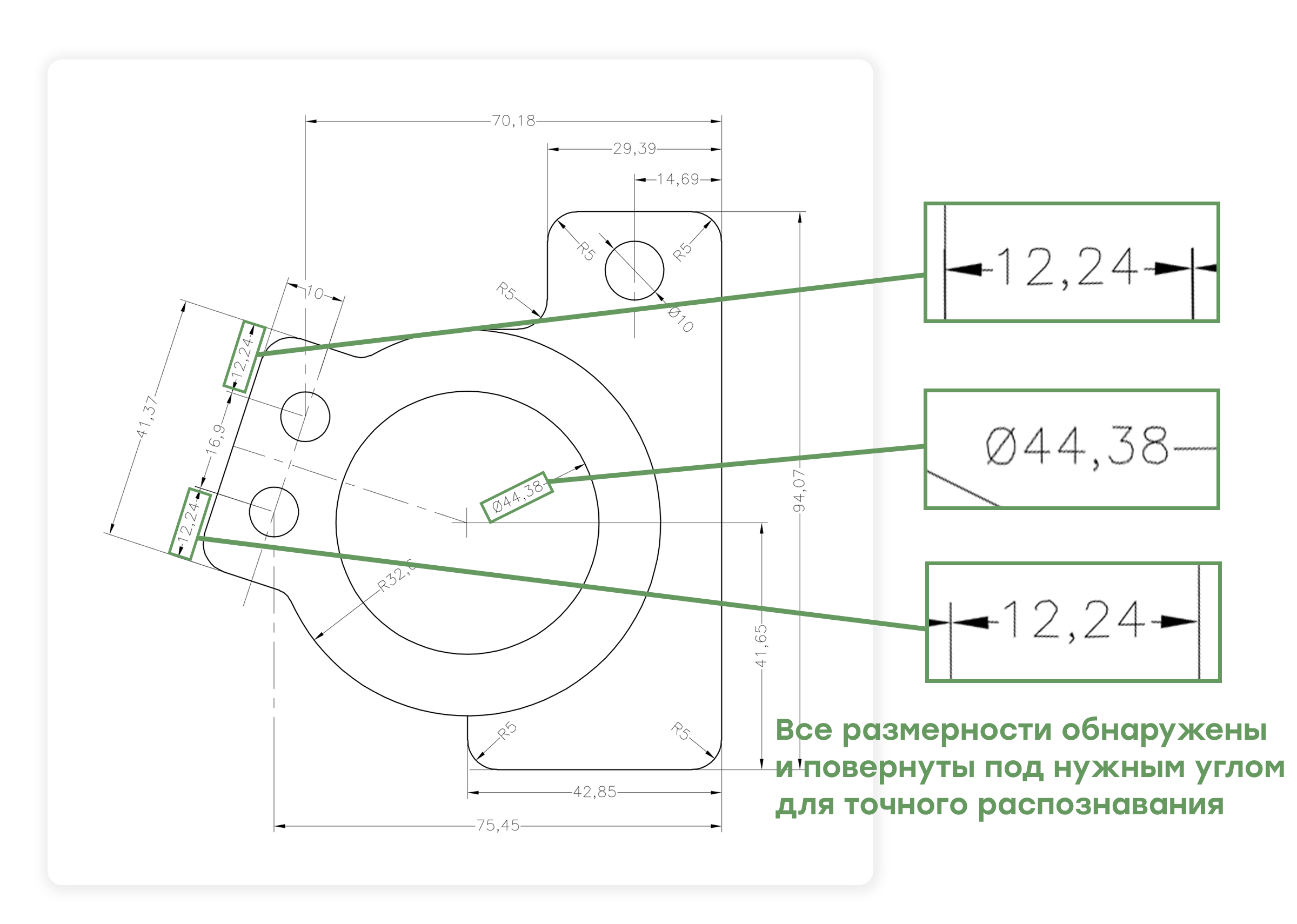
Каждая аннотация сохраняется в виде отдельных растровых изображений, готовых к распознаванию текста.
Шаг 3: извлечение данных
Далее каждая аннотация обрабатывается системой обнаружения символов. Мы выбрали движок искусственного интеллекта Tesseract, поскольку он обеспечивает высокую точность обнаружения и может обрабатывать сегментацию текста, т. е. текст с разной высотой, образующий несколько строк.
Сначала мы используем OpenCV для обнаружения текстовой области, чтобы повысить точность обнаружения текста в дальнейшем. Затем изображение передается механизму OCR для обнаружения всего текста и символов, присутствующих в аннотации.
Шаг 4. Анализ данных
Извлеченный текст и символы необходимо проанализировать и интерпретировать, чтобы получить понятные человеку данные для использования в системах клиента. Символы разделяются на группы, формирующие допуски, посадки и радиусы.
Шаг 5: Экспорт данных
В наших проектах по интеллектуальной обработке документов мы обычно используем один из трех способов извлечения данных:
- Данные извлекаются в формате JSON, что идеально подходит для встраивания данных в существующее программное обеспечение для дальнейшего анализа и хранения;
- Данные извлекаются в таблицу Excel, что позволяет получить удобный для чтения обзор данных;
- Данные подвергаются постобработке и отправляются в программное обеспечение для обработки цифровых документов напрямую, либо созданное на заказ в рамках проекта, либо в систему, которую уже использует клиент.
Формат извлечения данных полностью зависит от потребностей клиента и может быть скорректирован и изменен для лучшего удовлетворения потребностей клиента.
Почему стоит выбрать Технологику для обработки инженерных чертежей?
- Технологика с 2003 года работает на рынке разработки ПО и накопила большой опыт работы с самыми разными клиентами.
- В штате компании более чем 70 высококвалифицированных инженеров-программистов с большим опытом разработки сложного программного обеспечения как для стартапов, так и для международных компаний.
- Технологика более 5 лет занимается разработкой систем на основе искусственного интеллекта.
- Глубокая экспертиза в современных технологиях искусственного интеллекта и подходах к разработке систем, таких как data science, машинное обучение, OpenCV, Python, Tesseract и многие другие.
- Технологика является золотым сертифицированным партнером Microsoft. Технологика зарекомендовала себя как надежный партнер по аутсорсингу ИИ, имея отличный послужной список в области разработки ИИ и ML, подкрепленный обширным портфолио успешных проектов.