Извлечение данных из американских медицинских карт

Задача
Наш клиент, стартап в области электронного здравоохранения, обратился к нам с просьбой создать систему для обработки медицинских карт с целью извлечения релевантных данных, таких как данные пациента, лечение и стоимость.
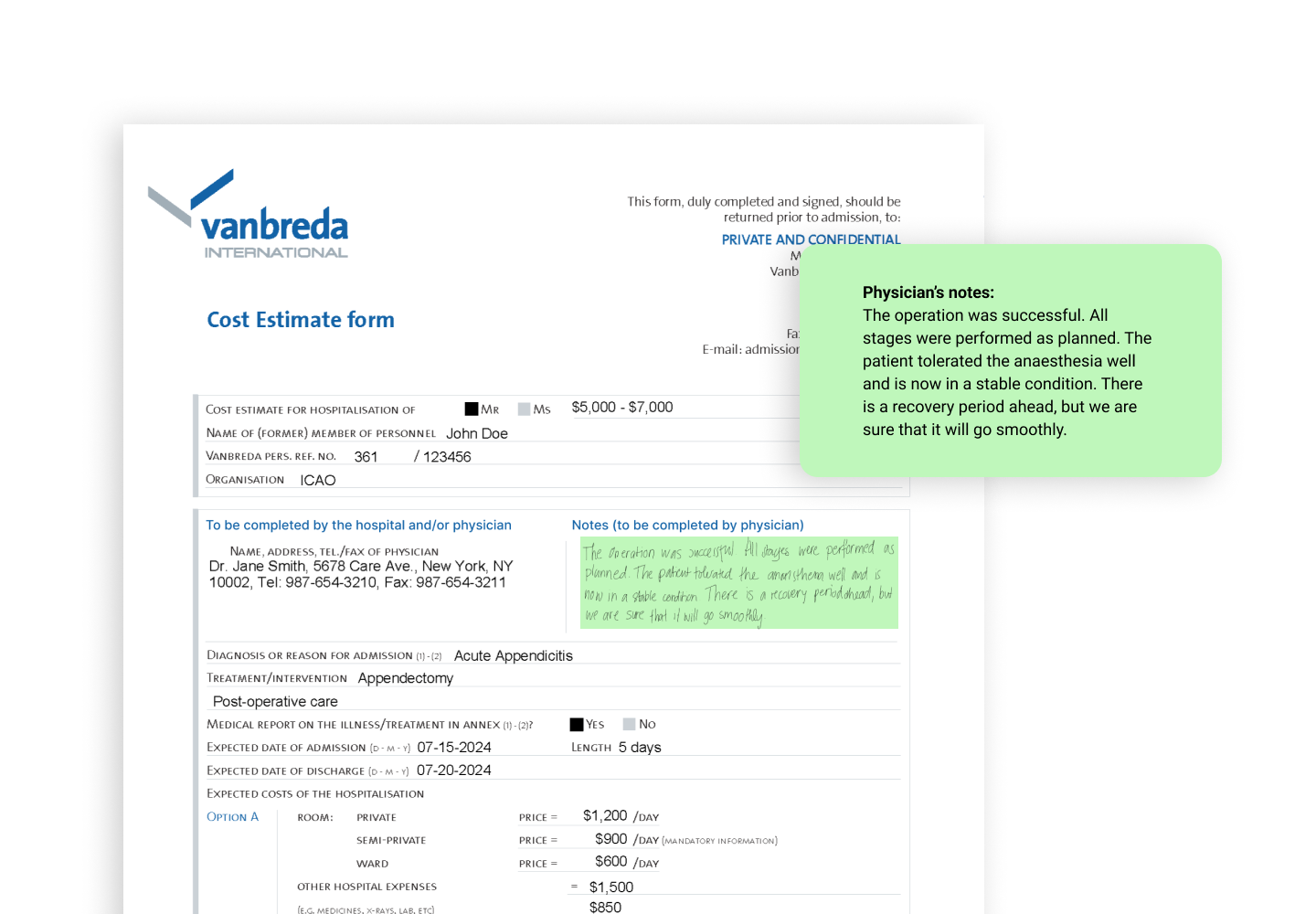
Медицинские карты - это сложные документы с переменной структурой и терминологией, неструктурированные данные, такие как заметки врача и рукописный текст, поэтому этот проект требует глубокой экспертизы в области современных алгоритмов компьютерного зрения и больших языковых моделей для разработки эффективного инструмента для интеллектуальной обработки медицинских карт.
Решение
Мы создали приложение для обработки медицинских записей на основе искусственного интеллекта, способное извлекать данные из многостраничных документов, независимо от их макета и формата.
Наше приложение извлекает только заданные данные, игнорируя несущественную информацию. Например инструкции для пациентов и заметки медсестер, а также учитывает различия в терминологии, используемой в разных больницах, чтобы обеспечить единообразие данных.
Обработка различных макетов
Поскольку каждая больница использует свой собственный формат медицинской карты, нашему клиенту было важно, чтобы система могла обрабатывать различные макеты документов.
Мы реализовали алгоритм, который определяет ключевые элементы на каждой странице, например часть контактных данных пациента или часть стоимости лечения, и извлекает данные с учетом нюансов макета. Модуль определения макета является гибким: когда появляется новый макет документа, мы можем легко обучить алгоритм обработке нового типа макета.
Разнообразная терминология
В медицинских записях из разных больниц часто используются разные слова для описания одного и того же. Такая вариативность терминологии не слишком удобна для извлечения и анализа данных. Наша команда машинного обучения внедрила несколько LLM для решения проблемы вариативности терминологии и обработки различных слов, описывающих один и тот же предмет, как одного и того же.

Используя возможности современных языковых моделей, наше приложение "понимает" смысл терминов, используемых в документах, и группирует объекты по смыслу, а не по конкретным словам, используемым для их описания.
Релевантный поиск данных
Медицинские документы, особенно те, в которых хранятся многолетние данные, часто представляют собой pdf-файлы объемом более 100 страниц. Поиск по таким массивным документам с помощью обычных краулеров может занять очень много времени, а поскольку релевантные данные часто разбросаны по нескольким страницам, традиционные методы обработки документов оказываются совершенно неэффективными.
Мы разработали модуль поиска документов, который использует мощные алгоритмы компьютерного зрения и OCR для быстрого обнаружения и выделения блоков текста с релевантной информацией, даже если данные разбросаны по нескольким страницам.
Приложение способно разделить один большой файл на несколько медицинских карт и извлечь данные из каждой из них, игнорируя несущественную информацию, например ЭКГ, изображения и указания пациента. Мы также внедрили модуль распознавания рукописного текста, чтобы расширить возможности приложения по распознаванию.
Результаты
Приложение уже внедрено в системы наших клиентов и показало, насколько эффективными могут быть современные системы искусственного интеллекта для обработки сложных документов.
Наша система успешно и с высокой скоростью извлекает необходимые данные, включая рукописный текст, из больших медицинских карт в формате PDF. Данные извлекаются в формате JSON и загружаются в базу данных нашего клиента для дальнейшего анализа.