AI-обработка документов для коллекторского агентства

Бизнес-логика
Заказчик - крупная коллекторская компания. Ежемесячно компания получает более 40 тысяч различных судебных постановлений по своим делам. Все эти документы сотрудникам необходимо самостоятельно просмотреть, найти там около 15 важных атрибутов и внести эту информацию во внутреннюю CRM систему.
На настоящий момент у клиента штат из 40 операторов, которые не успевают обрабатывать весь объем информации. С этим объемом справился бы штат из 60 человек, но так быстро укомплектовать штат сотрудников заказчик не может.
Сотрудники и так тратят более 65% своего рабочего времени на эту рутину, если они будут тратить больше времени, они просто не будут успевать делать все свои рабочие задачи.
Поэтому клиент задумался об автоматизации данного процесса, ведь анализ и распознавание текста, а также поиск нужной информации в тексте можно отдать искусственному интеллекту, освободив своих сотрудников для более важных задач. С этим Технологика и должна была помочь клиенту.
Решение
Судебные постановления, такие как судебные приказы, решения суда, определения суда, постановления президиума суда надзорной инстанции, формируются по гражданским делам должников и часто состоят из множества страниц. Коллекторские агентства получают их в формате pdf.
С такими документами хорошо справляются IDP технологии intelligent document processing).
Работа над созданием IDP-решения для заказчика строилась следующим образом:
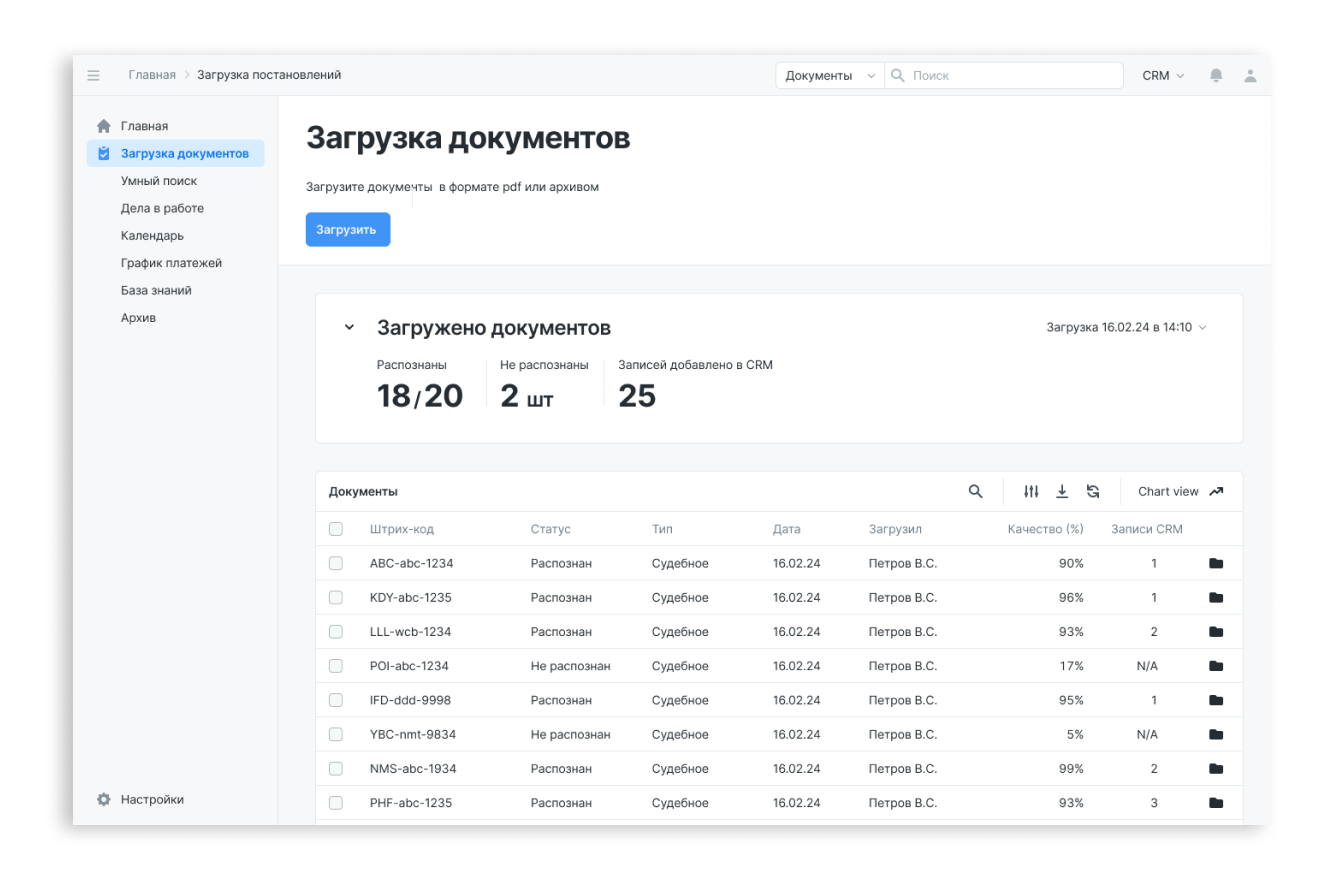
- Для начала мы создали внутренний веб-ресурс, на который сотрудники могут заливались документы для обработки.
- Обучаем нейронные сети:
- распознавать штрихкоды документов для правильного заполнения CRM системы документами;
- распознавать тексты постановлений;
- искать в текстах необходимые параметры для отправки в CRM систему
- Отправляем данные в CRM систему в JSON формате.

Штрихкоды
Здесь мы применили YOLO архитектуру для поиска штрихкодов. А в качестве инструментов применили Tesseract и Pytorch.
Извлечение текстов из pdf документов
Поскольку документы могли содержать текстовый слой, также как и не содержать его, мы применили два инструмента: Pdf2image и Tesseract.
Поиск необходимых атрибутов в текстах
После того как тексты успешно были распознаны, из них можно начинать выгружать ценные сведения. Мы обсуждали с клиентом применение локальной языковой модели (LLM) для выгрузки данных, поскольку в проекте речь идет о конфиденциальных и персональных данных. Но намного быстрее было создать парсер на базе Python, а также он выдавал более точные результаты.
Отправка данных в CRM систему
При помощи API мы связали внутренние ресурсы между собой, так что структурированные данные, полученные при помощи анализа документов, отправлялись напрямую в CRM систему в формате JSON.